

증권사에서 제공하는 COM, OCX, DLL 포맷의 API 라이브러리는 32비트로 개발되어 있습니다.
그래서 개발 프로그램에는 가상 메모리 공간 4GB 크기의 제약이 있고 64비트 기반의 최신 라이브러리와 연동하기 어려운 점이 있습니다. 그래서 API 라이브러리는 증권사 서버와의 커넥터 역할만 하도록 하고 별도의 로직 프로그램을 64비트로 개발하여 커넥터와 로직 프로그램을 연결하고 있습니다.
PC에 설치되어 있는 HTS의 OCX 모듈과 연계하는 방식이 아닌 DLL 연계 방식의 API는 커넥터를 여러 개 실행하여 다계정으로 API를 사용할 수 있게 되어 보다 고도화된 프로그램 로직 구현이 가능합니다.
Network bridge 방식으로 증권사 API 활용하기-1-Overview
증권사에서 제공하는 API는 32 비트 기반이기 때문에 트레이딩 프로그램을 64 비트로 개발하려면
프로그램을 API커넥터와 트레이딩프로그램 두 개로 분리하여 개발해야 합니다. 두 프로그램간의 데이터 교환을 위한 socket 기반 통신 프로토콜을 정의해 보고 실제 API커넥터가 트레이딩프로그램으로 접속패킷을 전송하는 과정을 살펴보겠습니다. API커넥터 분리를 통해 증권사 API별 커넥터가 트레이딩 프로그램에 접속하여 다양한 증권사의 데이터를 제공할 수 있고 API커넥터의 다계정 접속을 통하여 트레이딩 프로그램은 TR 전송수 제한의 제약으로부터 벗어날 수 있습니다. 또한 역으로 트레이딩 프로그램은 분산되어 있는 다수의 커넥터에게 카피트레이딩을 위한 매매신호를 제공할 수 있습니다.
The API provided by the stock company is based on 32-bit, so to develop the trading program in 64-bit, you must develop the program in two parts: API connector and trading program. Let's define a socket-based communication protocol for data exchange between the two programs, and look at the process of the actual API connector sending a connection packet to the trading program. By separating the API connector, a connector for each stock company API can connect to the trading program and provide data from various stock companies, and the trading program can escape from the constraints of the TR transmission limit through the multi-account access of the API connector. In addition, in reverse, the trading program can provide trading signals for copy trading to a large number of connectors that are distributed."
1. 증권사 API 제약사항
- OCX, COM, DLL 방식으로 제공: Python, Go 등 다양한 언어에서 Native로 개발 어려움
- 32 비트 API만 제공: 64 비트로 개발 불가, 64 비트 외부 라이브러리 사용 불가, 개발 프로그램 메모리 한계로 무한 상상력을 동원한 개발 불가
2. Network bridge 방식의 증권사 API 활용(이베스트투자증권 xingAPI 기준으로 설명)
- 32 비트 API 커넥터 프로그램 개발 : xingAPI의 DLL 활용하여 증권사 서버와 TR 직접 송수신
- 64 비트 트레이딩 프로그램 개발 : 증권사 서버로 TR 요청은 32 비트 API 커넥터 프로그램을 통해 요청
3. 서버-클라이언트 구조
- 서버: 트레이딩프로그램이 IOCP 방식 서버 역할
- 클라이언트: API커넥터가 클라이언트 역할
4. 패킷(프로토콜) 설계 고려사항(주식 전종목조회 T8430 기준으로)
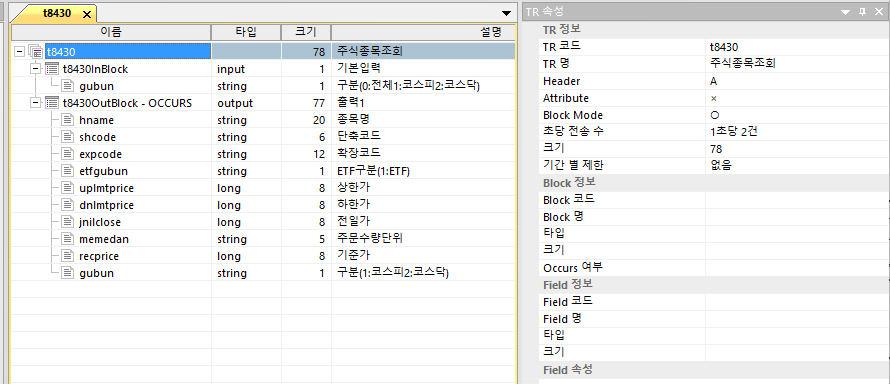
t8430OutBlock의 사이즈는 77바이트. 전종목 요청을 하면 상장종목이 2600개 이상이니까 77바이트 x 2600개의 OutBlock이 API커넥터(클라이언트)로 도착하게 되는데 이걸 그대로 트레이딩프로그램(서버)으로 전송하려면 어떻게 해야 할까요.
- 77바이트 OutBlock 1개씩 2600번 send 호출
- 77바이트 X 2600개 담긴 메모리 포인터 Send에 한 번에 담기
- TCP/IP MTU 사이즈 1500 고려하여 마진 50바이트 잡고 1450 바이트씩 나눠서 전송
3번 방식으로 하겠습니다.
OutBlock은 별도 패킷 구분 헤더가 없는데? API커넥터는 TR 요청당시 받아둔 RequestID를 갖고 있다가 도착한 OutBlock의 RequestID를 비교하여 어떤 TR의 OutBlock인지 구분 가능. API커넥터가 서버로 OutBlock을 전송할 때는 OutBlock을 한번 Wrapping 하여 추가 헤더를 붙이기로 결정합니다.
패킷 메모리관리는 동적할당? 정적할당? 대부분의 경우 패킷별로 동적할당 하여 송수신 후 메모리를 해제하지만 비슷한 데이터를 연속으로 수천 개씩 주고받으므로 메모리풀 관리방식을 사용하기로 결정합니다. 돌아다니는 테스트 결과에 따르면 new/malloc을 그냥 사용하면 메모리풀을 사용하는 것보다 20배 정도 느립니다. 또한 Outblock별로 사이즈가 다르므로 Heap영역의 메모리 단편화도 피할 수 없습니다. 절대적인 관점(사람이 느끼는)에서 프로그램은 그래도 충분히 빠르지만 프로그램을 분리하면서 데이터 송수신 퍼포먼스에 조금이라도 핸디캡을 갖게 되었으므로 패킷은 메모리풀방식으로 관리하고 캐시 hit rate 향상을 위해 LIFO로 관리하기로 합니다. Consumer는 각각 송/수신 스레드 1개이고 Producer도 현재는 1개일 건데 생산자:소비자=N:1로 할 것이므로 LIFO에서 ABA Problem은 발생하지 않는 구조. 서버/클라이언트에 빠른 디버깅을 위해 Diagnostics 모듈을 붙일 건데 이로 인한 메모리상태 열람에 따른 오버헤드를 최소화하기 위하여 메모리락은 Critical Section 대신 Reader-Writer 락을 사용하기로 결정합니다.
5. 패킷 메모리풀 구조 설계
다수의 패킷을 체인(Packet Chain) 방식으로 관리할 것입니다. 단, 서로 다른 패킷의 혼합(Packet Aggregation)은 나중에 최적화 구현 때 하기로 하고 일단은 하나의 체인은 공간이 남아있어도 한 종류의 데이터 타입만 담고 뒤의 다른 타입 데이터는 안 담기로 합니다.
코드로 구현할 메모리풀은 Data Management Services System(이하 DMSS)이라고 하고 구조는 아래 그림과 같습니다. PAYLOAD는 1450바이트로 할 것이고 512개를 정적으로 할당하여 관리하겠습니다. 512개의 기준은 T8430 OutBlock 사이즈 77바이트 곱하기 2600개 했을 때 적당한 선인 것 같아서 그렇게 정했습니다. 향후 기능개선을 하려면 메모리풀에 high water mark, low water mark 플래그를 두고 메모리풀이 동적으로 관리될 수 있도록 하면 됩니다만 저는 귀찮아서 그냥 이렇게 하는 대신 실제 구동할 때는 64GB 메모리 서버에서 엄청 여유있게 할당하려고 합니다.
동작 방식은 다음과 같습니다.
- DSM_ITEM 타입을 정의하고 Linked List로 관리할 수 있도록 Next 포인터를 둔다.
- 실제 데이터를 담을 Payload Chunk를 가리키는 포인터를 둔다. DSM_ITEM안에 정적으로 할당해도 되지만 Chunk끼리 연속된 메모리 공간을 갖도록 별도로 할당하고 포인팅 하기로 함. 향후 TR 응답 패킷의 메모리는 Release 호출하기 전까지는 반환이 안되니까(Real과 서비스 TR T1857은 해당 없음) lpPayload 포인터가 TR 응답 패킷을 직접 가리키도록 해도 되는데 이건 나중에 더 최적화 필요성을 느낄 때.
- 메모리풀 초기화 때 각 DSM_ITEM을 List로 연결하고 Head를 메모리풀에 연결해 둠.
- DSM_ITEM x개를 할당요청받으면 head부터 x개만큼 빼서 할당해 주고 반납 시 역으로 chain의 tail을 head에 붙이고 chain의 head를 메모리풀의 head로 한다.
여기까지 읽고 아래 그림을 봤는데 동작방식이 이해가 안 되면 뒤로 가기 누르시고 그냥 new/malloc 사용하시면 됩니다.

'프로그래밍 > C | C++' 카테고리의 다른 글
| Multiplexing Client Connections-1 (0) | 2023.06.30 |
|---|---|
| Network bridge 방식으로 증권사 API 활용하기-2 (0) | 2023.06.21 |
| [MFC] Modeless Dialog 생성하기 (0) | 2022.09.12 |
| [MFC] Build Openssl Statically Linked Against Windows (0) | 2022.08.27 |
| [MFC] C++ MiniDumpWriteDump (0) | 2022.08.12 |